
The Publication Bottleneck: Lossy compression in the Age of Omics
Valuable biological information is lost in the practice of publishing our work.

Charlie Kim
Author
June 5, 2026

Academic journals have served as a communication medium and record of scientific advances since the 17th century. In recent years, major progress in biology and medicine has led to increased investment into R&D, triggering an exponential proliferation of literature. PubMed now indexes over 40 million papers, with annual growth exceeding 1 million, and half of these records have been added in the last 15 years. Simultaneously, the density of information in every study is increasing, as evidenced by the dramatically increased use of supplementary materials, in part due to the widespread availability of high resolution measurement technologies (e.g. “omics”). As such, the rate of information growth significantly outpaces the volume of paper counts, making it increasingly difficult for researchers to keep pace with new findings.
As a consequence, communication via publication is subjected to a filtering process that reduces the available information by orders of magnitude – in other words, publication is a very lossy compression algorithm. For instance, a typical omics study measures tens of thousands of variables and might identify dozens to hundreds of significant features. Yet, a typical volcano plot often highlights only the top 20 features, with only a handful mentioned by gene symbol in the accompanying main text. Consequently, extracting the full biological implications is often difficult—if not impossible—without direct access to the raw data. This problem of discoverability is compounded because our primary portals for contextualizing findings, such as PubMed and Google Scholar, search abstracts and main text, respectively, which typically mention only a small fraction of the significant molecular features.
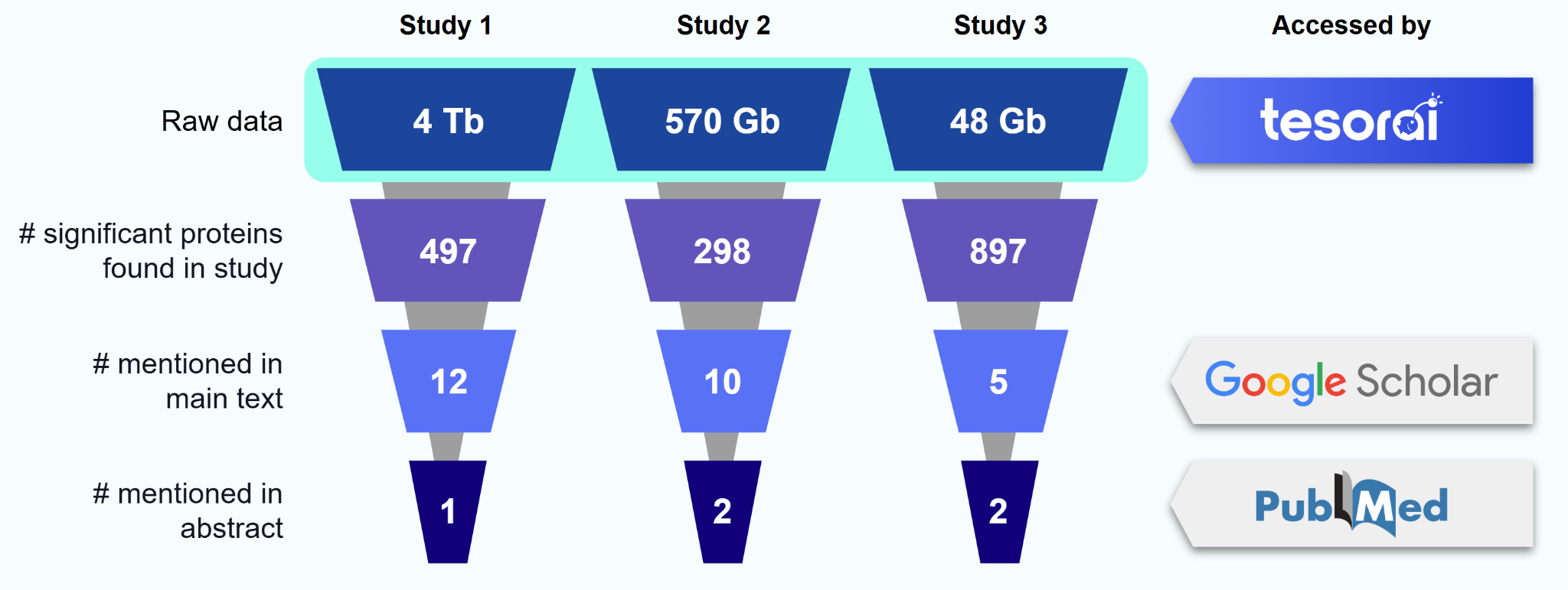
Our current publication and data sharing practices recover only a tiny fraction of the value from the original research investment. As omics methods become increasingly commoditized and higher-resolution molecular methods are deployed, the need for information compression will only worsen. Clearly, our current analysis and publication practices cannot scale to meet the demands of the coming years.
The future we envision addresses this by re-activating the dormant value of every dataset. This includes the capacity to contextualize new findings against the complete corpus of biological knowledge currently locked within raw data, enabling new insights. We believe that fundamentally changing how we manage and interpret raw data will dramatically accelerate life science research. Our launch of Tesorai Datasets is our first of many steps toward this future.
Resources
Explore publications, case studies, and guides to power your next experiment.
.svg)



We're here to help. Get in touch with our team or explore the platform yourself - and see how easy it is to get started
.svg)
Insights leveraging every byte of raw data